
KI-Algorithmen sind das Fundament jeder intelligenten Software – von der Produktempfehlung bis zur Betrugserkennung. Doch was macht einen Algorithmus „intelligent“, und welche Varianten eignen sich für welche Geschäftsziele? Dieser Artikel erklärt die Mechanik hinter der KI-Magie, und das ohne Fachjargon, aber mit Tiefgang.

Was ist ein KI-Algorithmus? Die Grunddefinition
Ein KI-Algorithmus unterscheidet sich fundamental von klassischen Algorithmen durch eine Fähigkeit: Er kann lernen. Während ein herkömmlicher Algorithmus starren Regeln folgt – etwa „Wenn Wert X größer als 100, dann führe Aktion Y aus“ – passt sich ein KI-Algorithmus kontinuierlich an neue Daten und Situationen an.
Stellen Sie sich vor, Sie schreiben ein Kochrezept auf. Ein klassischer Algorithmus folgt diesem Rezept Schritt für Schritt, immer gleich, unabhängig davon, ob die Tomaten süß oder sauer sind. Ein KI-Algorithmus verhält sich eher wie ein erfahrener Koch: Er schmeckt ab, justiert die Zutaten dynamisch und lernt aus jeder Mahlzeit, die er zubereitet. Diese adaptive Komponente macht den entscheidenden Unterschied.
In technischer Hinsicht ist ein KI-Algorithmus eine mathematische Funktion, die aus Eingabedaten (Input) ein gewünschtes Ergebnis (Output) erzeugt – jedoch nicht durch fest programmierte Wenn-dann-Regeln, sondern durch statistische Mustererkennung. Der Algorithmus identifiziert Zusammenhänge in großen Datenmengen und wendet diese Muster auf neue, unbekannte Situationen an. Genau diese Generalisierungsfähigkeit macht ihn „intelligent“.
Die praktische Relevanz für Unternehmen ist immens: Laut aktuellen Erhebungen nutzen bereits 35 % der Unternehmen weltweit KI in ihren Geschäftsabläufen, Tendenz stark steigend¹. In Deutschland liegt die Quote bei 20 %, wobei besonders große Unternehmen mit 48 % Nutzungsrate vorangehen². Der globale KI-Markt wird 2024 ein Volumen von 228 Milliarden US-Dollar erreichen und bis 2028 auf geschätzte 632 Milliarden US-Dollar wachsen³.
Wie funktionieren KI-Algorithmen? Die drei Lernphasen
KI-Algorithmen durchlaufen typischerweise drei Phasen, bevor sie produktiv einsetzbar sind. Verstehen Sie diese Mechanik, können Sie realistische Erwartungen an KI-Projekte formulieren und Ressourcen präziser planen.
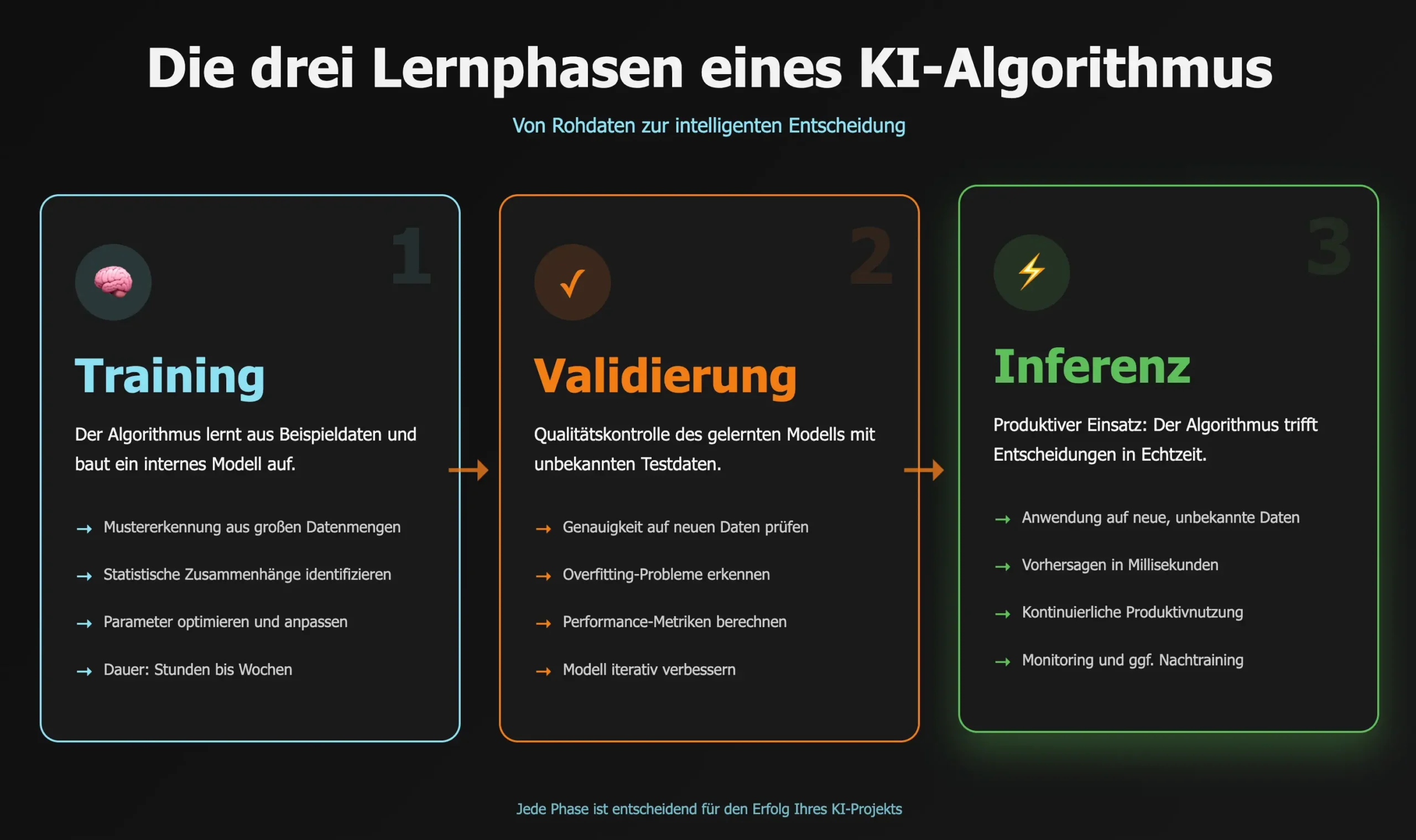
Training: In dieser Phase füttert man den Algorithmus mit Beispieldaten. Ein Spam-Filter etwa lernt anhand tausender E-Mails, welche Merkmale (bestimmte Wörter, Absenderadressen, Formatierungen) typisch für Spam sind. Der Algorithmus extrahiert statistische Muster und baut ein internes Modell auf. Je umfangreicher und qualitativ hochwertiger die Trainingsdaten, desto präziser das Ergebnis.
Validierung: Nach dem Training prüft man die Qualität des gelernten Modells anhand von Daten, die der Algorithmus noch nie gesehen hat. Diese Qualitätskontrolle ist essenziell: Ein Algorithmus könnte perfekt auf die Trainingsdaten abgestimmt sein (Overfitting), aber in der Realität versagen. Die Validierungsphase deckt solche Schwachstellen auf, bevor echte Geschäftsprozesse betroffen sind.
Inferenz: In dieser dritten Phase arbeitet der Algorithmus produktiv. Er wendet das gelernte Wissen auf neue, unbekannte Daten an – etwa jede eingehende E-Mail in Ihrem Posteingang. Die Inferenz sollte schnell erfolgen (Millisekunden bis Sekunden) und zuverlässige Ergebnisse liefern.
Ein Praxisbeispiel: Ihr E-Mail-System erhält täglich 500 Nachrichten. Der Spam-Filter wurde mit 100.000 historischen E-Mails trainiert, mit weiteren 20.000 validiert und klassifiziert nun jede neue Nachricht innerhalb von 0,2 Sekunden mit einer Genauigkeit von 99,2 %. Wenn die Spam-Muster sich ändern – etwa neue Betrugsmethoden auftauchen – sinkt die Erkennungsrate. Dann ist Nachtraining nötig, ein kontinuierlicher Prozess bei produktiven KI-Systemen.
Die wichtigsten KI-Algorithmus-Kategorien im Überblick
KI-Algorithmen lassen sich grob in vier Hauptkategorien einteilen, je nach Lernmethode. Die Wahl der richtigen Kategorie entscheidet über Erfolg oder Scheitern Ihres KI-Projekts.
| Kategorie | Lernprinzip | Typische Anwendungen | Datenbedarf |
|---|---|---|---|
| Überwachtes Lernen | Lernt aus gelabelten Beispielen | Bilderkennung, Betrugserkennung, Preisvorhersage | Hoch (Labels erforderlich) |
| Unüberwachtes Lernen | Entdeckt Muster eigenständig | Kundensegmentierung, Anomalieerkennung | Mittel (keine Labels nötig) |
| Verstärkendes Lernen | Lernt durch Trial & Error mit Feedback | Robotik, Spielstrategien, Routenoptimierung | Gering (Simulation möglich) |
| Deep Learning | Mehrschichtige neuronale Netze | Spracherkennung, autonomes Fahren, Textgenerierung | Sehr hoch |
Überwachtes Lernen (Supervised Learning) ist die am weitesten verbreitete Methode. Der Algorithmus lernt aus Beispielen, bei denen sowohl Input als auch gewünschter Output bekannt sind. Sie zeigen ihm 10.000 Bilder von Katzen (gelabelt als „Katze“) und 10.000 Bilder von Hunden (gelabelt als „Hund“). Der Algorithmus lernt die visuellen Unterscheidungsmerkmale und kann anschließend neue Bilder korrekt klassifizieren.
Geschäftsrelevante Anwendungen: Kreditwürdigkeitsprüfung (historische Daten über Kreditnehmer mit bekanntem Zahlungsausfall), Kundenabwanderung (Churn Prediction basierend auf historischen Kündigungsmustern), Qualitätskontrolle in der Produktion (fehlerhafte vs. einwandfreie Produkte).
Unüberwachtes Lernen (Unsupervised Learning) kommt ohne vorgegebene Labels aus. Der Algorithmus erhält nur die Rohdaten und sucht eigenständig nach Strukturen. Kennen Sie das? Ihre Marketingabteilung hat 50.000 Kundendaten, weiß aber nicht, wie sie diese sinnvoll segmentieren soll. Ein Clustering-Algorithmus gruppiert Kunden automatisch nach gemeinsamen Merkmalen – etwa Kaufverhalten, Demografie, Interaktionsmuster – ohne dass Sie vorab definieren müssen, wie viele Segmente es geben soll.
Typische Einsatzgebiete: Market Basket Analysis (welche Produkte kaufen Kunden zusammen?), Anomalieerkennung im Netzwerkverkehr (abweichendes Verhalten deutet auf Cyberangriffe hin), Empfehlungssysteme (Kunden mit ähnlichem Kaufverhalten erhalten ähnliche Produktvorschläge).
Verstärkendes Lernen (Reinforcement Learning) funktioniert nach dem Prinzip von Belohnung und Bestrafung. Der Algorithmus probiert verschiedene Aktionen aus und erhält Feedback: Führt die Aktion zum Ziel, gibt es eine positive Belohnung; verfehlt sie das Ziel, eine negative. Durch millionenfaches Wiederholen optimiert der Algorithmus seine Strategie.
Praxisbeispiel: Ein Logistikunternehmen optimiert Lieferrouten. Der Algorithmus testet unzählige Routenvarianten in Simulationen, erhält positives Feedback für schnelle, kostengünstige Routen und negatives für Umwege oder Verzögerungen. Nach einigen hunderttausend Simulationen findet er Routen, die menschliche Planer nicht intuitiv gewählt hätten, aber 12 % Treibstoffkosten einsparen.
Neuronale Netze und Deep Learning bilden eine Sonderkategorie, die auf allen drei vorherigen Lernmethoden aufbauen kann. Diese Algorithmen imitieren grob die Struktur des menschlichen Gehirns: viele miteinander verbundene „Neuronen“ (mathematische Funktionen) in mehreren Schichten. Je mehr Schichten, desto „tiefer“ das Netzwerk – daher der Begriff Deep Learning.
Deep-Learning-Modelle eignen sich besonders für komplexe Muster in unstrukturierten Daten: Bilderkennung, Sprachverarbeitung, Textgenerierung. ChatGPT etwa basiert auf einem neuronalen Netz mit hunderten Milliarden Parametern, trainiert auf riesigen Textmengen. Die Kehrseite: Deep Learning benötigt enorme Rechenressourcen und Datenmengen. Für die meisten mittelständischen Geschäftsprobleme sind einfachere Algorithmen oft effizienter und ausreichend.
KI-Algorithmen in der Unternehmenspraxis
Die Theorie ist das eine – doch wie setzt man KI-Algorithmen konkret ein? Laut einer Bitkom-Umfrage nutzen 86 % der deutschen Unternehmen, die KI einsetzen, diese im Kundenkontakt⁴. Weitere beliebte Anwendungsfelder: Marketing und Kommunikation (47 %), IT-Sicherheit, Produktion und Logistik.
Marketing: Personalisierung ist der Königsweg zu höheren Conversion-Raten. Ein E-Commerce-Unternehmen aus dem Mittelstand setzt einen Recommendation-Algorithmus ein, der das Browsing- und Kaufverhalten von 200.000 Kunden analysiert. Basierend auf ähnlichen Nutzerprofilen schlägt das System Produkte vor – ähnlich wie Amazon oder Netflix. Das Ergebnis: 18 % höhere durchschnittliche Warenkorbwerte, weil Kunden relevante Ergänzungsprodukte entdecken.
Predictive Analytics geht noch einen Schritt weiter: Welche Kunden werden mit hoher Wahrscheinlichkeit in den nächsten 90 Tagen abwandern? Ein Algorithmus analysiert Verhaltensmuster – etwa sinkende Login-Frequenz, weniger Käufe, vermehrte Support-Anfragen – und identifiziert Abwanderungskandidaten frühzeitig. Die Marketingabteilung kann gezielt Rückgewinnungsmaßnahmen einleiten.

Produktion: Predictive Maintenance (vorausschauende Wartung) spart Millionen. Sensoren an Produktionsmaschinen erfassen kontinuierlich Vibrations-, Temperatur- und Leistungsdaten. Ein KI-Algorithmus lernt, welche Datenmuster auf bevorstehende Ausfälle hindeuten. Statt starrer Wartungsintervalle („alle 6 Monate“) erfolgt Wartung nur bei tatsächlichem Bedarf. Ein produzierendes Unternehmen aus Baden-Württemberg reduzierte ungeplante Stillstände um 37 % und Wartungskosten um 22 %.

Qualitätskontrolle durch Computer Vision: Kameras fotografieren jedes gefertigte Teil, ein Deep-Learning-Algorithmus prüft auf Defekte – Risse, Verfärbungen, Maßabweichungen. Die Erkennungsrate liegt bei über 99,5 %, deutlich höher als bei manueller Prüfung. Für Ihre Rechtsabteilung wichtig: Dokumentieren Sie Trainings- und Validierungsdaten sorgfältig, um Produkthaftungsansprüche abzuwehren.
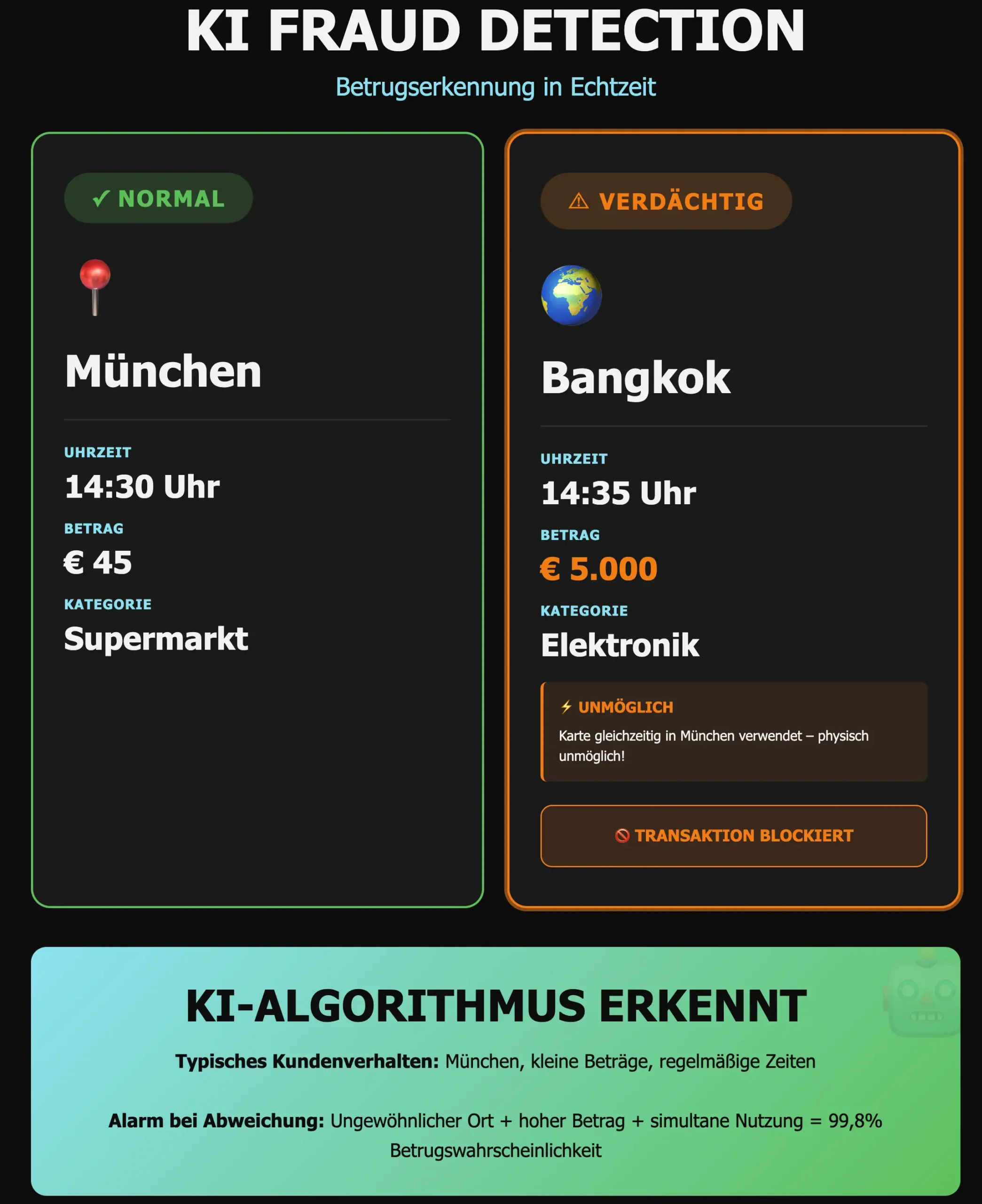
Finance: Fraud Detection ist ein klassisches KI-Feld. Banken und Zahlungsdienstleister analysieren Transaktionsmuster in Echtzeit. Ein Algorithmus lernt, was typisches Kundenverhalten ist (Ort, Uhrzeit, Betragshöhen) und schlägt bei Abweichungen Alarm. Kauft ein Kunde, der normalerweise in München einkauft, plötzlich in Bangkok 5.000 € Elektronik – während seine Karte gleichzeitig in München verwendet wird – blockiert das System die Transaktion.
Risikobewertung: Versicherungen nutzen KI-Algorithmen, um Versicherungsnehmer präziser einzustufen. Statt pauschaler Risikokategorien ermöglicht KI individualisierte Prämien basierend auf hunderten Variablen. Das erhöht die Fairness, wirft aber auch ethische Fragen auf (siehe Kapitel „Grenzen und Herausforderungen“).
HR: Bewerberselektion durch KI ist umstritten, aber weit verbreitet. Algorithmen screenen Lebensläufe, bewerten Qualifikationen anhand von Keywords und Rankings früherer Bewerber. Vorteil: Zeit- und Kostenersparung, standardisierter Prozess. Nachteil: Risiko von Bias (Voreingenommenheit), wenn historische Einstellungsdaten diskriminierende Muster enthalten.
Mitarbeiterbindung: Welche Faktoren führen zu hoher Zufriedenheit, welche zu Kündigungen? Ein HR-Analytics-Algorithmus identifiziert Frühwarnzeichen – etwa abnehmende Leistung, seltenere Teilnahme an Meetings, vermehrte Krankheitstage – und ermöglicht proaktive Gespräche.
Der Unterschied zu klassischen Algorithmen
Warum reichen klassische Algorithmen nicht aus, wenn doch seit Jahrzehnten Software erfolgreich Geschäftsprozesse steuert? Die Antwort liegt in der Art der Probleme.
Klassische Algorithmen eignen sich hervorragend für deterministische Aufgaben mit klaren Regeln: Sortieren von Daten, Berechnung von Zinsen, Validierung von Eingabeformaten. Wenn Sie genau beschreiben können, wie die Lösung aussieht, programmieren Sie einen klassischen Algorithmus. Er arbeitet zuverlässig, schnell, nachvollziehbar.
KI-Algorithmen übernehmen dort, wo Regeln zu komplex oder unbekannt sind. Wie erkennt man einen Hund auf einem Foto? Welche E-Mail ist Spam? Welcher Kunde wird abwandern? Solche Fragen lassen sich nicht in einfachen Wenn-dann-Regeln abbilden. Die Muster sind zu subtil, die Variablen zu zahlreich.
| Merkmal | Klassischer Algorithmus | KI-Algorithmus |
|---|---|---|
| Regeln | Explizit programmiert | Aus Daten gelernt |
| Anpassung | Manuell durch Entwickler | Automatisch durch Training |
| Ergebnis | Immer gleich (deterministisch) | Wahrscheinlichkeitsbasiert |
| Transparenz | Vollständig nachvollziehbar | Oft Black Box |
| Datenbedarf | Gering | Hoch |
| Laufzeit | Meist schneller | Oft ressourcenintensiver |
Ein Beispiel: Frühe Spam-Filter arbeiteten mit festen Regeln („blockiere alle E-Mails mit ‚Viagra‘ im Betreff“). Spammer passten sich schnell an (schrieben „V!agra“ oder nutzten Bilder statt Text). Moderne KI-Spam-Filter lernen aus Millionen Beispielen und erkennen auch verschleierte Muster, neue Spam-Varianten und kontextabhängige Merkmale.
Wann sind klassische Algorithmen die bessere Wahl? Wenn Prozesse klar definiert, unveränderlich und nachvollziehbar sein müssen. Buchhaltungssoftware, Lagerverwaltung, Gehaltsabrechnung – hier wäre KI Overkill. Die Kosten (Daten sammeln, Training, Wartung) übersteigen den Nutzen.
Hybride Ansätze kombinieren beide Welten: Ein regelbasiertes System trifft Vorentscheidungen, KI-Algorithmen verfeinern schwierige Fälle. So behält man Kontrolle und Transparenz bei Standardprozessen, profitiert aber von KI-Intelligenz bei Ausnahmen.
Welcher KI-Algorithmus passt zu Ihrem Projekt?
Die Wahl des richtigen Algorithmus ist entscheidend. 83 % der Organisationen, die KI-Plattformen implementiert haben, erzielten innerhalb von nur drei Monaten eine positive Rendite⁵ – vorausgesetzt, sie wählten den passenden Ansatz.
Checkliste: Welche Lernmethode passt?
Überwachtes Lernen wählen, wenn:
- Sie gelabelte Trainingsdaten haben oder erstellen können
- Das Ziel klar definiert ist (Klassifikation oder Vorhersage)
- Hohe Genauigkeit wichtiger ist als Interpretierbarkeit
- Beispiele: Betrugserkennung, Bildklassifikation, Verkaufsprognosen
Unüberwachtes Lernen wählen, wenn:
- Keine gelabelten Daten verfügbar sind
- Sie Muster entdecken wollen, ohne vorab zu wissen, welche
- Kundensegmentierung oder Anomalieerkennung im Fokus stehen
- Beispiele: Marktsegmentierung, Netzwerküberwachung, Datenexploration
Verstärkendes Lernen wählen, wenn:
- Es um sequenzielle Entscheidungen geht (mehrere Schritte zum Ziel)
- Sie eine Simulationsumgebung haben
- Das System durch Trial & Error lernen soll
- Beispiele: Robotersteuerung, Spielstrategien, Ressourcenallokation
Deep Learning wählen, wenn:
- Sie mit unstrukturierten Daten arbeiten (Bilder, Audio, Text)
- Sehr große Datenmengen verfügbar sind (Millionen Beispiele)
- Hohe Rechenleistung (GPUs) zur Verfügung steht
- Beispiele: Spracherkennung, medizinische Bildanalyse, Chatbots
Die Rolle der Datenqualität kann nicht genug betont werden. „Garbage in, garbage out“ gilt bei KI noch stärker als bei klassischer Software. Laut einer aktuellen Studie nennen 71 % der deutschen Unternehmen, die keine KI nutzen, fehlendes Wissen als Hauptgrund⁶. Auf Platz zwei: Unklarheit über rechtliche Folgen (58 %), gefolgt von Datenschutzbedenken (53 %) und Schwierigkeiten mit Datenverfügbarkeit oder -qualität (45 %).
Investieren Sie in Datenaufbereitung: Bereinigung, Normalisierung, Validierung. Ein KI-Projekt ist zu 80 % Datenarbeit und nur zu 20 % Algorithmus-Tuning. Unterschätzen Sie diesen Punkt nicht.
Build vs. Buy: Eigene Entwicklung oder Standard-Tools? Für spezialisierte Anwendungen (etwa Ihr Geschäftsmodell ist einzigartig) lohnt sich Eigenentwicklung mit Data Scientists. Für Standard-Use-Cases (Chatbots, Sentiment-Analyse, Objekterkennung) greifen Sie auf Cloud-Plattformen zurück (AWS, Azure, Google Cloud). Diese bieten trainierte Modelle, die Sie mit wenig Aufwand an Ihre Daten anpassen – sogenanntes Transfer Learning.
Grenzen und Herausforderungen von KI-Algorithmen
KI ist mächtig, aber kein Allheilmittel. Wer Grenzen kennt, vermeidet teure Fehlschläge.
Black-Box-Problem: Viele moderne KI-Algorithmen, insbesondere Deep-Learning-Modelle, arbeiten wie eine Blackbox. Sie liefern Ergebnisse, aber niemand kann im Detail nachvollziehen, warum. Ein neuronales Netz mit 100 Millionen Parametern ist mathematisch korrekt, aber praktisch nicht interpretierbar. In regulierten Branchen – Banken, Versicherungen, Medizin – ist das problematisch. Die EU-KI-Verordnung (AI Act), die im August 2025 vollständig in Kraft tritt, verlangt bei Hochrisiko-KI-Systemen Erklärbarkeit⁷.
Lösungsansätze: Explainable AI (XAI) entwickelt Methoden, um KI-Entscheidungen nachvollziehbar zu machen. LIME (Local Interpretable Model-agnostic Explanations) oder SHAP (SHapley Additive exPlanations) sind Techniken, die zeigen, welche Eingabevariablen welchen Einfluss hatten. Für Ihre Compliance-Abteilung ein Muss.
Bias und ethische Fragestellungen: KI-Algorithmen lernen aus historischen Daten – und damit auch aus menschlichen Vorurteilen, die in diesen Daten stecken. Ein berühmtes Beispiel: Ein Bewerbungs-KI eines großen Tech-Konzerns benachteiligte systematisch Frauen, weil historische Einstellungsdaten männlich dominiert waren. Der Algorithmus lernte: „Männliche Bewerber werden häufiger eingestellt“ und reproduzierte dieses diskriminierende Muster.
Auch in Deutschland sind solche Fälle dokumentiert: Algorithmen zur Kreditvergabe, die bestimmte Postleitzahlen benachteiligen, oder automatisierte Bewerbungssysteme, die Migrationshintergrund indirekt nachteilig bewerten. Die DSGVO verlangt, dass automatisierte Entscheidungen mit erheblicher Wirkung für Betroffene (etwa Kreditablehnung) nachvollziehbar sein müssen. Unternehmen haften bei Diskriminierung durch KI.
Rechenressourcen und Skalierbarkeit: Training großer KI-Modelle verschlingt enorme Ressourcen. Ein modernes Sprachmodell wie GPT-4 benötigt Trainingskosten im Millionenbereich und Energiemengen, die dem Jahresverbrauch kleiner Städte entsprechen. Für mittelständische Unternehmen sind solche Projekte unrealistisch. Die gute Nachricht: Kleinere, spezialisierte Modelle reichen für die meisten Geschäftsprobleme aus und laufen auch auf Standard-Hardware.
Inferenz-Kosten sind ebenfalls relevant. Jede KI-Anfrage verursacht Rechenaufwand. Bei Millionen Nutzern summiert sich das. Cloud-Anbieter berechnen pro API-Aufruf – ein unerwarteter Kostenfaktor, wenn Ihr Chatbot viral geht.
DSGVO-konforme Anwendung in Europa: Datenschutz ist in Europa kein Nice-to-have, sondern Pflicht. KI-Algorithmen verarbeiten oft personenbezogene Daten. Sie müssen sicherstellen: Einwilligung, Zweckbindung, Datensparsamkeit, Speicherbegrenzung. HubSpot bietet etwa europäische Rechenzentren in Deutschland für DSGVO-konforme CRM-Nutzung – ein wichtiges Verkaufsargument für datenschutzbewusste Kunden.
Besonders heikel: Profilbildung. Wenn Ihr KI-System Nutzerprofile erstellt, um Verhalten vorherzusagen (etwa Kaufwahrscheinlichkeit), greift Artikel 22 DSGVO. Betroffene haben das Recht auf menschliche Prüfung automatisierter Entscheidungen mit rechtlicher oder ähnlich erheblicher Wirkung.
Ausblick: Wie entwickeln sich KI-Algorithmen weiter?
Die KI-Landschaft verändert sich rasant. Was 2024 State-of-the-Art war, ist 2025 bereits Standard⁸. Einige Trends zeichnen sich ab:
Foundation Models und Transfer Learning: Statt jedes Mal von Grund auf zu trainieren, nutzen Unternehmen zunehmend Foundation Models – große, vortrainierte Modelle wie GPT, BERT oder CLIP. Diese werden mit wenig Aufwand auf spezifische Aufgaben angepasst (Fine-Tuning). Das senkt Kosten und Zeitaufwand dramatisch. Ein mittelständisches Unternehmen kann so in Wochen statt Jahren produktive KI-Systeme aufbauen.
Edge AI: Algorithmen auf dem Gerät: Bisher laufen die meisten KI-Algorithmen in der Cloud – Daten werden hochgeladen, verarbeitet, Ergebnisse zurückgeschickt. Edge AI verschiebt die Verarbeitung direkt auf das Gerät (Smartphone, IoT-Sensor, Industrieroboter). Vorteil: Niedrigere Latenz, Datenschutz (Daten verlassen das Gerät nicht), Unabhängigkeit von Internetverbindung. Aktuelle Smartphone-Chips haben bereits dedizierte KI-Beschleuniger (NPUs).
Automatisiertes Machine Learning (AutoML): Der größte Engpass bei KI-Projekten ist fehlendes Fachwissen. Nur 26 % der Unternehmen haben laut Boston Consulting Group die notwendigen Fähigkeiten entwickelt, um über Proof-of-Concepts hinaus echten Wert zu generieren⁹. AutoML-Tools automatisieren Algorithmus-Auswahl, Hyperparameter-Tuning und Feature-Engineering. Plattformen wie Google AutoML, H2O oder DataRobot ermöglichen auch Nicht-Data-Scientists erfolgreiche KI-Projekte.
Die Demokratisierung von KI-Technologie: No-Code-Plattformen machen KI für jeden zugänglich. Sie müssen keinen Python-Code mehr schreiben, um einen Chatbot zu trainieren oder ein Bilderkennungsmodell zu erstellen. Drag-and-drop-Interfaces, visuelle Workflows, integrierte Templates – die Einstiegshürde sinkt kontinuierlich. Microsoft Copilot und Google Workspace AI integrieren KI-Funktionen direkt in Alltagstools. Bis 2026 ist KI kein Wettbewerbsvorteil mehr, sondern Hygienefaktor wie E-Mail oder CRM¹⁰.
Für Ihr Unternehmen bedeutet das: Warten Sie nicht länger. Die Frage ist nicht mehr „ob“, sondern „wie schnell“ Sie KI einsetzen. Beginnen Sie mit überschaubaren Projekten – einem Chatbot im Kundenservice, Predictive Maintenance an einer kritischen Maschine, automatisierten Produktempfehlungen im Webshop. Sammeln Sie Erfahrung, bauen Sie interne Kompetenz auf, skalieren Sie dann.
Fazit: KI-Algorithmen sind das Herzstück der digitalen Transformation. Sie unterscheiden sich von klassischer Software durch ihre Fähigkeit, aus Daten zu lernen und sich anzupassen. Für Entscheider gilt: Verstehen Sie die Grundprinzipien, wählen Sie die passende Algorithmus-Kategorie für Ihr Problem, investieren Sie in hochwertige Daten und beachten Sie rechtliche Rahmenbedingungen. Mit dieser Basis steht erfolgreichen KI-Projekten nichts im Weg.
Fußnoten & Quellen
¹ Hostinger/Kodexolabs (2024): KI-Statistik: Fakten und Trends im Jahr 2025. 35% der Unternehmen weltweit nutzen KI in ihren Geschäftsabläufen.
² Statistisches Bundesamt (Destatis, November 2024): Jedes fünfte Unternehmen nutzt künstliche Intelligenz. Erhebung zur Nutzung von IKT in Unternehmen 2024.
³ IDC via Statista (August 2024): Umsatz im Bereich Künstliche Intelligenz weltweit im Jahr 2024 und Prognose für 2028.
⁴ Bitkom (März 2025): Umfrage zum Einsatz von KI in deutschen Unternehmen. 86% der Unternehmen setzen KI im Kundenkontakt ein.
⁵ G2/Vention (2024): 83% der Organisationen mit KI-Plattformen erzielten innerhalb von drei Monaten positive ROI.
⁶ Statistisches Bundesamt (Destatis, November 2024): Gründe für Nichtgebrauch von KI in Unternehmen. 71% nennen fehlendes Wissen als Hauptgrund.
⁷ Plotdesk (August 2025): KI-Trends 2025 – EU AI Act tritt August 2025 vollständig in Kraft.
⁸ Plotdesk (August 2025): KI-Trends 2025: Was 2024 State-of-the-Art war, ist 2025 Standard.
⁹ Boston Consulting Group (2024): Nur 26% der Unternehmen haben notwendige Fähigkeiten für KI-Wertgenerierung entwickelt.
¹⁰ Gartner/Plotdesk (2025): 75% der Unternehmen werden bis Ende 2025 KI nutzen. Ab 2026 ist KI Hygienefaktor statt Wettbewerbsvorteil.








